
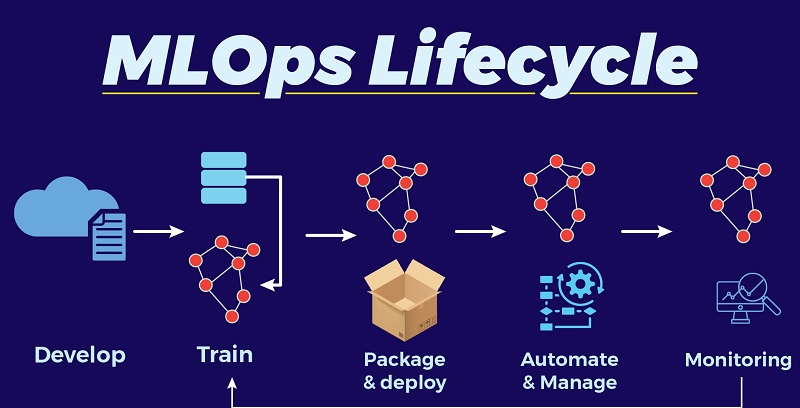
By concentrating on the effective and dependable operationalization of machine learning models, Machine Learning Operations (MLOps) fills the gap between model creation and deployment. Adopting mlops best practice approaches for monitoring and maintaining deployed models is essential. This guarantees that even when the data that models handle changes over time, they will still function accurately and provide value. Model performance may deteriorate in the absence of strong monitoring and maintenance procedures, which could result in imprecise forecasts and, eventually, bad business choices.
Tracking Model Drift: Identifying Performance Decay
Data drift is one of the biggest obstacles to sustaining model performance. This happens when the model’s training data’s statistical characteristics evolve over time. Numerous things, like shifts in consumer behaviour, industry trends, or data collection procedures, may be to blame for this. Monitoring model drift is crucial for spotting possible declines in performance. To do this, input data distributions must be continuously checked for variations from the initial training data. Early drift detection can be aided by methods such as visual examination of data distributions and statistical distance measures.
Establishing Alerts and Automated Retraining Workflows
It is crucial to have systems in place to deal with drift once it is identified. Potential problems can be promptly identified by setting up warnings based on pre-set drift metrics criteria. Automated retraining operations, which entail training the model on fresh data that mirrors the current data distribution, may be initiated by these notifications. This guarantees that the model remains current and keeps producing precise forecasts. Performance degradation is minimized by automating the retraining process, which also speeds up the response to data drift and decreases manual involvement.
Extensive Performance Tracking: Exceeding Precision
A thorough monitoring approach includes measuring a variety of performance metrics, even if accuracy is an important statistic. Depending on the particular model and its use, these measures may include precision, recall, F1-score, and AUC. Keeping an eye on these measures helps pinpoint specific areas that want work and offers a more detailed picture of model performance. Monitoring latency and resource usage (CPU, RAM) is crucial in addition to performance measurements because these elements can affect both the model’s overall user experience and operating costs.
Retraining Techniques: Improving Model Adaptability
Retraining must be done carefully to maintain model performance. Different retraining methods might be utilized depending on drift type and degree. Periodic retraining involves regular model retraining regardless of drift. As mentioned, trigger-based retraining only retrains the model when drift exceeds a threshold. Continuous learning adds new data to the model. The optimum course of action depends on data drift, retraining cost, and performance degradation. By carefully considering these factors and implementing a robust monitoring and maintenance plan, organizations can ensure their ML models continue to deliver value.